
Good news for Hadoop developers who want to use Microsoft Windows OS for their development activities. Finally Apache Hadoop 2.2.0 release officially supports for running Hadoop on Microsoft Windows as well. But the bin distribution of Apache Hadoop 2.2.0 release does not contain some windows native components (like winutils.exe, hadoop.dll etc). As a result, if we try to run Hadoop in windows, we'll encounter ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path.
In this article, I'll describe how to build bin native distribution from source codes, install, configure and run Hadoop in Windows Platform.
Tools and Technologies used in this article :
- Apache Hadoop 2.2.0 Source codes
- Windows 7 OS
- Microsoft Windows SDK v7.1
- Maven 3.1.1
- Protocol Buffers 2.5.0
- Cygwin
- JDK 1.6
Build Hadoop bin distribution for Windows
a. Download and install Microsoft Windows SDK v7.1.
b. Download and install Unix command-line tool Cygwin.
c. Download and install Maven 3.1.1.
d. Download Protocol Buffers 2.5.0 and extract to a folder (say c:\protobuf).
e. Add Environment Variables JAVA_HOME, M2_HOME and Platform if not added already.
Add Environment Variables:

Note :
- Variable name Platform is case sensitive. And value will be either x64 or Win32 for building on a 64-bit or 32-bit system.
- If JDK installation path contains any space then use Windows shortened name (say 'PROGRA~1' for 'Program Files') for the JAVA_HOME environment variable.
Edit Path Variable to add bin directory of Cygwin (say C:\cygwin64\bin), bin directory of Maven (say C:\maven\bin) and installation path of Protocol Buffers (say c:\protobuf).
Edit Path Variable:

f. Download hadoop-2.2.0-src.tar.gz and extract to a folder having short path (say c:\hdfs) to avoid runtime problem due to maximum path length limitation in Windows.
g. Select Start --> All Programs --> Microsoft Windows SDK v7.1 and open Windows SDK 7.1 Command Prompt. Change directory to Hadoop source code folder (c:\hdfs). Execute mvn package with options -Pdist,native-win -DskipTests -Dtar to create Windows binary tar distribution.
Windows SDK 7.1 Command Prompt
Setting SDK environment relative to C:\Program Files\Microsoft SDKs\Windows\v7.1\. Targeting Windows 7 x64 Debug
C:\Program Files\Microsoft SDKs\Windows\v7.1>cd c:\hdfs C:\hdfs>mvn package -Pdist,native-win -DskipTests -Dtar [INFO] Scanning for projects… [INFO] ------------------------------------------------------------------------ [INFO] Reactor Build Order: [INFO] [INFO] Apache Hadoop Main [INFO] Apache Hadoop Project POM [INFO] Apache Hadoop Annotations [INFO] Apache Hadoop Assemblies [INFO] Apache Hadoop Project Dist POM [INFO] Apache Hadoop Maven Plugins [INFO] Apache Hadoop Auth [INFO] Apache Hadoop Auth Examples [INFO] Apache Hadoop Common [INFO] Apache Hadoop NFS [INFO] Apache Hadoop Common Project [INFO] Apache Hadoop HDFS [INFO] Apache Hadoop HttpFS [INFO] Apache Hadoop HDFS BookKeeper Journal [INFO] Apache Hadoop HDFS-NFS [INFO] Apache Hadoop HDFS Project [INFO] hadoop-yarn [INFO] hadoop-yarn-api [INFO] hadoop-yarn-common [INFO] hadoop-yarn-server [INFO] hadoop-yarn-server-common [INFO] hadoop-yarn-server-nodemanager [INFO] hadoop-yarn-server-web-proxy [INFO] hadoop-yarn-server-resourcemanager [INFO] hadoop-yarn-server-tests [INFO] hadoop-yarn-client [INFO] hadoop-yarn-applications [INFO] hadoop-yarn-applications-distributedshell [INFO] hadoop-mapreduce-client [INFO] hadoop-mapreduce-client-core [INFO] hadoop-yarn-applications-unmanaged-am-launcher [INFO] hadoop-yarn-site [INFO] hadoop-yarn-project [INFO] hadoop-mapreduce-client-common [INFO] hadoop-mapreduce-client-shuffle [INFO] hadoop-mapreduce-client-app [INFO] hadoop-mapreduce-client-hs [INFO] hadoop-mapreduce-client-jobclient [INFO] hadoop-mapreduce-client-hs-plugins [INFO] Apache Hadoop MapReduce Examples [INFO] hadoop-mapreduce [INFO] Apache Hadoop MapReduce Streaming [INFO] Apache Hadoop Distributed Copy [INFO] Apache Hadoop Archives [INFO] Apache Hadoop Rumen [INFO] Apache Hadoop Gridmix [INFO] Apache Hadoop Data Join [INFO] Apache Hadoop Extras [INFO] Apache Hadoop Pipes [INFO] Apache Hadoop Tools Dist [INFO] Apache Hadoop Tools [INFO] Apache Hadoop Distribution [INFO] Apache Hadoop Client [INFO] Apache Hadoop Mini- [INFO]
[INFO] ------------------------------------------------------------------------ [INFO] Building Apache Hadoop Main 2.2.0 [INFO] ------------------------------------------------------------------------ [INFO] [INFO] --- maven-enforcer-plugin:1.3.1:enforce (default) @ hadoop-main --- [INFO] [INFO] --- maven-site-plugin:3.0:attach-descriptor (attach-descriptor) @ hadoop-main ---
Note: I have pasted only the starting few lines of huge logs generated by maven. This building step requires Internet connection as Maven will download all the required dependencies.
h. If everything goes well in the previous step, then native distribution hadoop-2.2.0.tar.gz will be created inside C:\hdfs\hadoop-dist\target\hadoop-2.2.0 directory.
Install Hadoop
a. Extract hadoop-2.2.0.tar.gz to a folder (say c:\hadoop).
b. Add Environment Variable HADOOP_HOME and edit Path Variable to add bin directory of HADOOP_HOME (say C:\hadoop\bin).
Add Environment Variables:

Configure Hadoop
Make following changes to configure Hadoop
- File: C:\hadoop\etc\hadoop\core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file.—>
<!— Put site-specific property overrides in this file. —>
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>fs.defaultFS:
The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.
- File: C:\hadoop\etc\hadoop\hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file.—>
<!— Put site-specific property overrides in this file. —>
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/data/dfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/data/dfs/datanode</value> </property> </configuration>dfs.replication:
Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time.
dfs.namenode.name.dir:
Determines where on the local filesystem the DFS name node should store the name table(fsimage). If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy.
dfs.datanode.data.dir:
Determines where on the local filesystem an DFS data node should store its blocks. If this is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices. Directories that do not exist are ignored.
Note: Create namenode and datanode directory under c:/hadoop/data/dfs/. - File: C:\hadoop\etc\hadoop\yarn-site.xml
<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file.—> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.application.classpath</name> <value> %HADOOP_HOME%\etc\hadoop, %HADOOP_HOME%\share\hadoop\common*, %HADOOP_HOME%\share\hadoop\common\lib*, %HADOOP_HOME%\share\hadoop\mapreduce*, %HADOOP_HOME%\share\hadoop\mapreduce\lib*, %HADOOP_HOME%\share\hadoop\hdfs*, %HADOOP_HOME%\share\hadoop\hdfs\lib*,
%HADOOP_HOME%\share\hadoop\yarn*, %HADOOP_HOME%\share\hadoop\yarn\lib* </value> </property> </configuration>yarn.nodemanager.aux-services:
The auxiliary service name. Default value is omapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class:
The auxiliary service class to use. Default value is org.apache.hadoop.mapred.ShuffleHandler
yarn.application.classpath:
CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries.
- File: C:\hadoop\etc\hadoop\mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. —>
<!— Put site-specific property overrides in this file. —>
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>mapreduce.framework.name:
The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn.
Format namenode
For the first time only, namenode needs to be formatted.
Command Prompt
Microsoft Windows [Version 6.1.7601]
Copyright (c) 2009 Microsoft Corporation. All rights reserved.
C:\Users\abhijitg>cd c:\hadoop\bin
c:\hadoop\bin>hdfs namenode -format
13/11/03 18:07:47 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = ABHIJITG/x.x.x.x
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.2.0
STARTUP_MSG: classpath = <classpath jars here>
STARTUP_MSG: build = Unknown -r Unknown; compiled by ABHIJITG on 2013-11-01T13:42Z
STARTUP_MSG: java = 1.7.0_03
************************************************************/
Formatting using clusterid: CID-1af0bd9f-efee-4d4e-9f03-a0032c22e5eb
13/11/03 18:07:48 INFO namenode.HostFileManager: read includes:
HostSet(
)
13/11/03 18:07:48 INFO namenode.HostFileManager: read excludes:
HostSet(
)
13/11/03 18:07:48 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
13/11/03 18:07:48 INFO util.GSet: Computing capacity for map BlocksMap
13/11/03 18:07:48 INFO util.GSet: VM type = 64-bit
13/11/03 18:07:48 INFO util.GSet: 2.0% max memory = 888.9 MB
13/11/03 18:07:48 INFO util.GSet: capacity = 2^21 = 2097152 entries
13/11/03 18:07:48 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
13/11/03 18:07:48 INFO blockmanagement.BlockManager: defaultReplication = 1
13/11/03 18:07:48 INFO blockmanagement.BlockManager: maxReplication = 512
13/11/03 18:07:48 INFO blockmanagement.BlockManager: minReplication = 1
13/11/03 18:07:48 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
13/11/03 18:07:48 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false
13/11/03 18:07:48 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
13/11/03 18:07:48 INFO blockmanagement.BlockManager: encryptDataTransfer = false
13/11/03 18:07:48 INFO namenode.FSNamesystem: fsOwner = ABHIJITG (auth:SIMPLE)
13/11/03 18:07:48 INFO namenode.FSNamesystem: supergroup = supergroup
13/11/03 18:07:48 INFO namenode.FSNamesystem: isPermissionEnabled = true
13/11/03 18:07:48 INFO namenode.FSNamesystem: HA Enabled: false
13/11/03 18:07:48 INFO namenode.FSNamesystem: Append Enabled: true
13/11/03 18:07:49 INFO util.GSet: Computing capacity for map INodeMap
13/11/03 18:07:49 INFO util.GSet: VM type = 64-bit
13/11/03 18:07:49 INFO util.GSet: 1.0% max memory = 888.9 MB
13/11/03 18:07:49 INFO util.GSet: capacity = 2^20 = 1048576 entries
13/11/03 18:07:49 INFO namenode.NameNode: Caching file names occuring more than 10 times
13/11/03 18:07:49 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
13/11/03 18:07:49 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
13/11/03 18:07:49 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
13/11/03 18:07:49 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
13/11/03 18:07:49 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time
is 600000 millis
13/11/03 18:07:49 INFO util.GSet: Computing capacity for map Namenode Retry Cache
13/11/03 18:07:49 INFO util.GSet: VM type = 64-bit
13/11/03 18:07:49 INFO util.GSet: 0.029999999329447746% max memory = 888.9 MB
13/11/03 18:07:49 INFO util.GSet: capacity = 2^15 = 32768 entries
13/11/03 18:07:49 INFO common.Storage: Storage directory \hadoop\data\dfs\namenode has been successfully formatted.
13/11/03 18:07:49 INFO namenode.FSImage: Saving image file \hadoop\data\dfs\namenode\current\fsimage.ckpt_00000000000000
00000 using no compression
13/11/03 18:07:49 INFO namenode.FSImage: Image file \hadoop\data\dfs\namenode\current\fsimage.ckpt_0000000000000000000 o
f size 200 bytes saved in 0 seconds.
13/11/03 18:07:49 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
13/11/03 18:07:49 INFO util.ExitUtil: Exiting with status 0
13/11/03 18:07:49 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at ABHIJITG/x.x.x.x
************************************************************/
Start HDFS (Namenode and Datanode)
Command Prompt
C:\Users\abhijitg>cd c:\hadoop\sbin
c:\hadoop\sbin>start-dfs
Two separate Command Prompt windows will be opened automatically to run Namenode and Datanode.
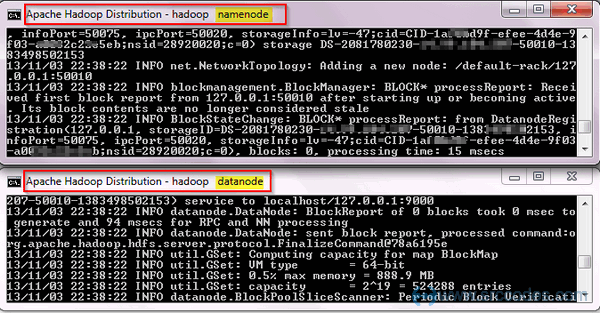
Start MapReduce aka YARN (Resource Manager and Node Manager)
Command Prompt
C:\Users\abhijitg>cd c:\hadoop\sbin
c:\hadoop\sbin>start-yarn
starting yarn daemons
Similarly, two separate Command Prompt windows will be opened automatically to run Resource Manager and Node Manager.
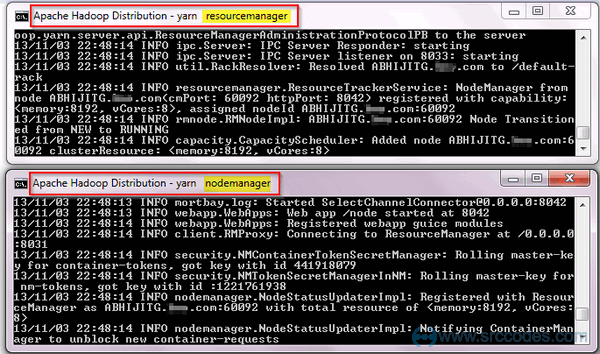
Verify Installation
If everything goes well then you will be able to open the Resource Manager and Node Manager at http://localhost:8042 and Namenode at http://localhost:50070.
Node Manager: http://localhost:8042/
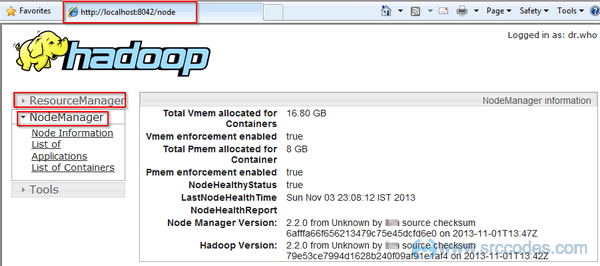
Namenode: http://localhost:50070
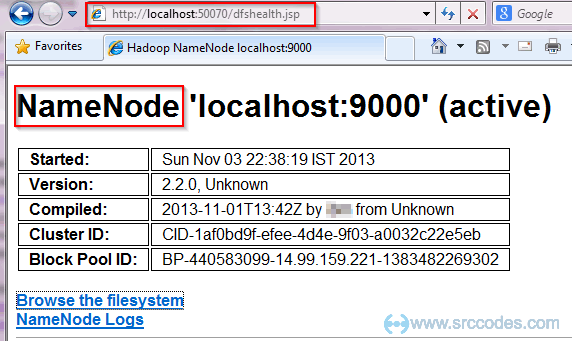
Run wordcount MapReduce job
Follow the post Run Hadoop wordcount MapReduce Example on Windows
Stop HDFS & MapReduce
Command Prompt
C:\Users\abhijitg>cd c:\hadoop\sbin c:\hadoop\sbin>stop-dfs SUCCESS: Sent termination signal to the process with PID 876. SUCCESS: Sent termination signal to the process with PID 3848.c:\hadoop\sbin>stop-yarn stopping yarn daemons SUCCESS: Sent termination signal to the process with PID 5920. SUCCESS: Sent termination signal to the process with PID 7612.
INFO: No tasks running with the specified criteria.
Download SrcCodes
All code samples shown in this post are available on Github





