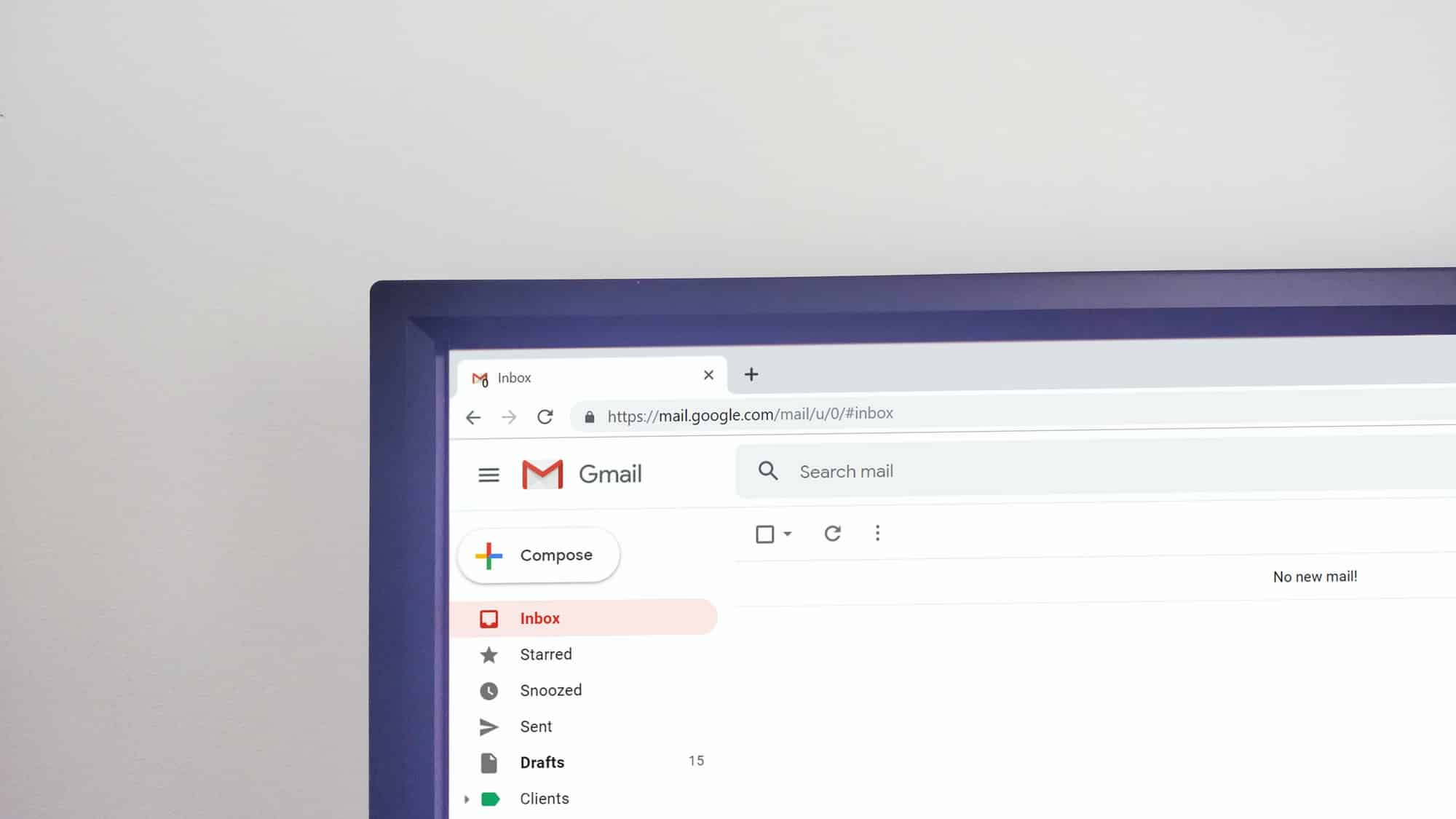
4,153,406 hits in single day!
Sounds like a really big number for many of us. I was surprised when I noticed this in Production ELK for the first time. I didn't expect that many hits for an application with only 5 microservices. That too for a Beta application with a handful (~2k) of users. It will grow to 25+ microservices within next one year. Once migration completes, millions of users will use this application. I can not imagine where this number shall skyrocket then.
We should Log smartly, not in Volume. Its great if this is already taken care of in your application. But if you are looking for more, then reading this post might add value.
As a developer, we at times don't give much thought to what we are logging and how much we are logging. Everything is taken care of by the underlying logging framework. It has hardly any cost considerations for us, the developers.
While talking about cost, following few comes to mind.
- IO:
- Logger - To write log statements in file or console
- Beats - To collect data from environment.
- Network:
- Beats - To ship data from edge machines to Logstash
- Logstash - To ship processed data to preferred "Stash"
- Processing:
- Beats: To parse collected raw data.
- Logstash: To ingest, parse, transform, ship log to destination
- Elasticsearch: To index, search & run analytics.
- Storage: To store & retain huge logs from all sources for a certain period of time
Enough talk! Let's see what we can optimize using the following two configurations. There are more. Plan is to reduce log volume without impacting your existing applications.
- Customizing Logger Name Length
- Customizing Stack Traces
1. Customizing Logger Name Length
Define appropriate length for shortenedLoggerNameLength of LogstashEncoder in Logback configuration.
How?
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<shortenedLoggerNameLength>30</shortenedLoggerNameLength>
</encoder>
It works in same way %logger{length} conversion pattern works.
Let's do the Math
Take an example of bare minimum Logger name com.srccodes.lob.project.service.api.MyService (46 characters). Now if we shorten to c.s.l.p.s.a.MyService (21 characters), we'll save 25 characters for each hit. So total unrealized savings of storage & bandwidth would be 103+ millions (4153406 X 25 = 103835150) characters each day in the current Beta application. Just to give a rough idea, 1 million characters is equivalent of ~23 hours 8 min of speech duration.
Conversion Word
%logger{length}will shorten the logger name, usually without significant loss of meaning. Setting the value of length option to zero constitutes an exception. It will cause the conversion word to return the sub-string right to the rightmost dot character in the logger name. The next table provides examples of the abbreviation algorithm in action.
Conversion specifier Logger name Result %logger mainPackage.sub.sample.Bar mainPackage.sub.sample.Bar %logger{0} mainPackage.sub.sample.Bar Bar %logger{5} mainPackage.sub.sample.Bar m.s.s.Bar %logger{10} mainPackage.sub.sample.Bar m.s.s.Bar %logger{15} mainPackage.sub.sample.Bar m.s.sample.Bar %logger{16} mainPackage.sub.sample.Bar m.sub.sample.Bar %logger{26} mainPackage.sub.sample.Bar mainPackage.sub.sample.Bar Please note that the rightmost segment in a logger name is never abbreviated, even if its length is longer than the length option. Other segments may be shortened to at most a single character but are never removed.
2. Customizing Stack Traces
logstash-logback-encoder includes a very powerful throwableConverter called ShortenedThrowableConverter. It'll be a good idea to customize stack traces for optimizations.
rootCauseFirst is a cool feature. It is very handy to see the root cause first rather than browsing through chains of "Caused by:". Logs gets truncated beyond buffer_size of Logstash (65536 bytes on Logstash >= 5.1). In such cases, root cause will be lost and toubleshooting might be a nightmare.
Otherside, maxLength & shortenedClassNameLength will help to reduce log message size.
- Limiting the number of stackTraceElements per throwable (applies to each individual throwable. e.g. caused-bys and suppressed)
- Limiting the total length in characters of the trace
- Abbreviating class names
- Filtering out consecutive unwanted stackTraceElements based on regular expressions.
- Using evaluators to determine if the stacktrace should be logged.
- Outputing in either 'normal' order (root-cause-last), or root-cause-first.
- Computing and inlining hexadecimal hashes for each exception stack
For example:
<encoder class="net.logstash.logback.encoder.LogstashEncoder"> <throwableConverter class="net.logstash.logback.stacktrace.ShortenedThrowableConverter"> <maxDepthPerThrowable>30</maxDepthPerThrowable> <maxLength>2048</maxLength> <shortenedClassNameLength>20</shortenedClassNameLength> <exclude>sun\.reflect\..*\.invoke.*</exclude> <exclude>net\.sf\.cglib\.proxy\.MethodProxy\.invoke</exclude> <evaluator class="myorg.MyCustomEvaluator"/> <rootCauseFirst>true</rootCauseFirst> <inlineHash>true</inlineHash> </throwableConverter> </encoder>
Though the cost of storage, network & processing power are getting cheaper by the day, applications are also scaling up and scaling out in many folds over time. So, I believe, it is important to optimize as much as possible.
Please share your thoughts and experiences on this. Thanks in advance.